Als je gaat klussen aan je auto is het goed om te weten wat er ongeveer onder de motorkap zit. Als je aan de slag gaat met SEO is het ook goed om te weten hoe een zoekmachine werkt. Dit artikel krijg je antwoord op de vraag: Hoe werken zoekmachines?
- Hoe werken zoekmachines?
- Hoe zoekmachinespiders het internet crawlen
- Hoe alle data wordt geïndexeerd
- Hoe zoekmachines pagina’s ranken
Hoe werken zoekmachines?
Zoekmachines speuren het complete web af met behulp van zogenaamde zoekmachine spiders (of webcrawlers). Alle gevonden pagina’s worden vervolgens gekopieerd en in een grote database geplaatst.
Op het moment dat je een zoekopdracht uitvoert toont Google (of een andere zoekmachine) binnen een fractie van een seconde een lijst met websites die antwoord kunnen geven op jouw vraag. Maar hoe weet Google wat het beste resultaat is?
Hier gaat een complex proces aan vooraf van crawlen, indexeren en ranken.
- Crawlen: Het verzamelen van nieuwe of geüpdatete content op het internet. Dit wordt gedaan door zogenaamde webcrawlers of spiders.
- Indexeren: Het archiveren en ordenen van alle gevonden content in een grote database (ook wel een zoekindex genoemd).
- Ranken (rangschikken): Het rangschikken van de geïndexeerde content zodat jij het beste antwoord op je vraag krijgt.
Wat is crawlen
Crawlen is het proces waarbij zoekmachinespiders (of webcrawlers) zoeken naar nieuwe of geüpdatete content op het internet. Google gebruikt bijvoorbeeld de Googlebot, terwijl Bing gebruik maakt van de Bingbot.
Bij content hoef je niet alleen te denken aan webpagina’s, maar ook aan pdf-bestanden, afbeeldingen, video’s, formulieren, etc.
Hoe webcrawlers te werk gaan
Het crawlen (of fetchen) van het complete wereldwijde web is een enorm complex proces waarbij de crawlers iedere webpagina op het internet proberen te vinden. Het zoeken naar nieuwe, of geüpdatete pagina’s doen crawlers op drie verschillende manieren:
- Via interne- en externe links
- Via een XML-sitemap
- Indexering aanvragen via Google Search Console
Interne- en externe links
Wanneer de crawler een webpagina bezoekt wordt deze pagina gekopieerd en opgeslagen in een zoekindex. Vervolgens noteert de crawler alle links op de pagina en voegt deze toe aan een crawllijst.

Dit is dan ook de reden dat backlinks, maar ook de navigatiestructuur van je website zo enorm belangrijk is. Als je geen backlinks, en geen goede structuur hebt kunnen crawlers jouw webpagina’s niet goed bereiken en zul je dus minder goed gevonden in de zoekmachine.
Via een XML-sitemap
Een XML-sitemap is een map met een overzicht van alle pagina’s op jouw website. Je kunt deze sitemap onder andere indienen via Google Search Console en Bing Webmaster Tools.
Via deze tool kun je controleren of je website al een XML sitemap heeft. Vaak is de URL van een sitemap https://jouwdomein.nl/sitemap.xml of https://jouwdomein.nl/sitemap_index.xml.
XML-sitemap indienen via Google Search Console
Ga naar je Google Search Console account en ga via het linkermenu naar Index → Sitemaps. Voer hier de URL van je sitemap in.
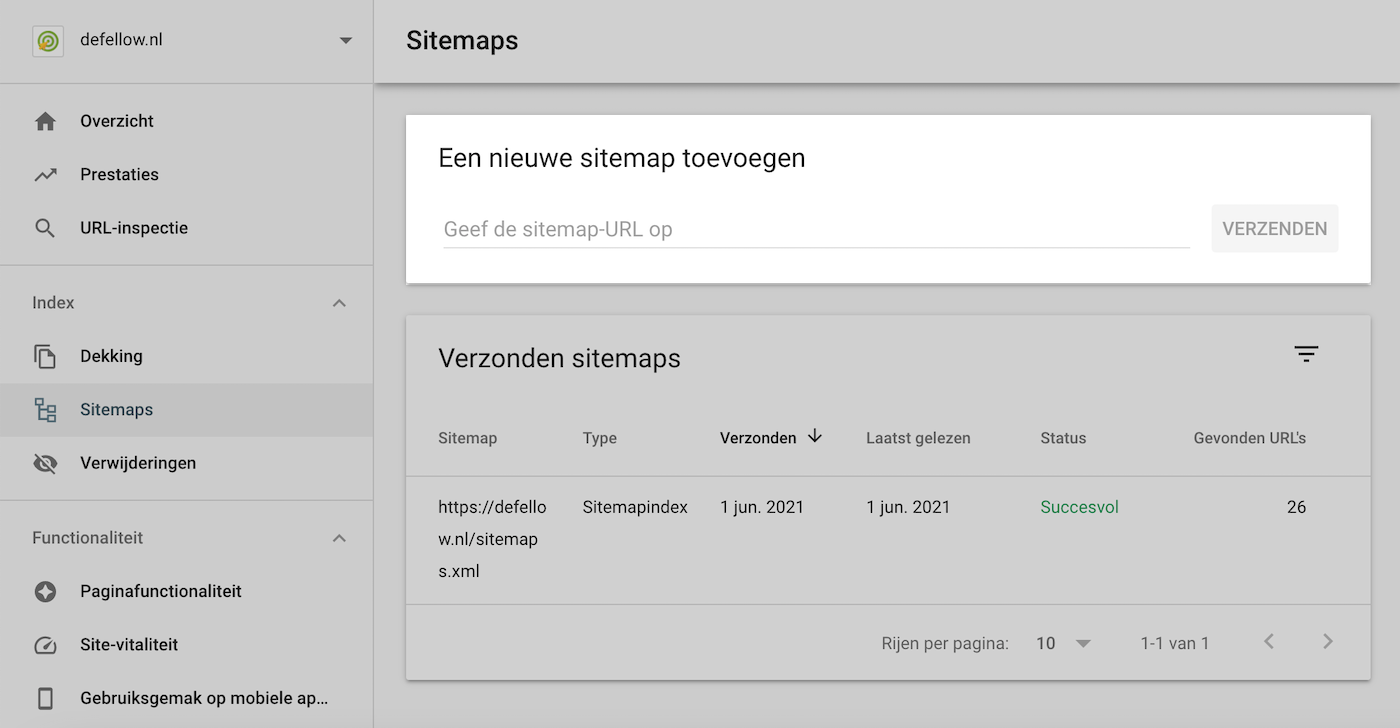
Je kunt de locatie van je XML-sitemap ook aangeven via het robots.txt bestand.
Indexering aanvragen via Google Search Console
Heb je een nieuwe webpagina gepubliceerd, of heb je een pagina geüpdatet? Dan kan het even duren voordat deze door de webcrawler gevonden wordt.
Als je wilt dat je website snel wordt geïndexeerd kun je via Google Search Console handmatig indexering aanvragen.
Ga naar Google Search Console en typ de URL van de nieuwe of geüpdatete pagina in de zoekbalk bovenaan. Klik vervolgens op Indexering aanvragen.
Je webpagina wordt nu aan een prioriteitscrawlwachtrij toegevoegd en wordt vaak dezelfde dag nog gecrawld en geïndexeerd.

Crawlfrequentie
Het is niet zo dat een pagina iedere keer als deze wordt ontdekt ook opnieuw wordt gecrawld. Dit zou namelijk betekenen dat sommige pagina’s bijna iedere dag gecrawld worden. Dit zal inefficiënt zijn is zonde van het crawlbudget.
Daarom maakt Google gebruik van een crawlwachtrij. Waar in de rij een pagina terecht komt hangt af van drie factoren:
- De PageRank van de URL.
- De frequentie dat een pagina veranderd.
- Of de pagina nieuw is of niet.
Primaire & secundaire crawler
Google maakt gebruik van twee verschillende crawlers:
- Mobiele crawler (Googlebot Smartphone)
- Desktop crawler (Googlebot Desktop)
Eén van de twee is de primaire crawler, de andere de secundaire. Voor alle websites die zijn gelanceerd na 1 juli 2019 is de mobiele crawler primair. Bij oudere websites kan het zijn dat de desktop crawler primair is, maar daar zal binnenkort verandering inkomen. Dit wordt ook wel mobile first indexing genoemd.
Alle webpagina’s worden standaard gecrawld met de primaire crawler. Daarnaast crawlt Google slechts een paar pagina’s opnieuw met de secundaire crawler. Dit om te kijken of je website ook op het andere apparaat goed werkt.
Tip! Neem de mobiele variant van je website als leidraad. Google doet dat namelijk ook.
Content dat niet wordt gecrawld
Niet alle content kan door een zoekmachine worden gecrawld. Het kan dus voorkomen dat een pagina (al dan niet bewust) wordt overgeslagen. Vaak heeft dit één van de volgende redenen:
- De pagina mag niet worden gecrawld volgens het robots.txt bestand.
- De pagina wordt afgeschermd door middel van een inlogscherm.
- De pagina is niet of moeilijk bereikbaar
- Er is door middel van een noindex tag aangegeven dat de pagina niet geïndexeerd mag worden.
Zorg er dus altijd voor dat je belangrijkste content goed bereikbaar is. Hierbij is een goede webitestructuur een belangrijke voorwaarde. Zo voorkom je dat er naar sommige pagina’s niet verwezen wordt (ook wel orphan pages genoemd).

Veelvoorkomende fouten waardoor crawlers je website niet vinden
Mensen hebben het niet in de gaten dat webcrawlers moeite hebben om hun webpagina’s te vinden. Als een bezoeker de content makkelijk weet te vinden betekent dit niet dat een zoekmachine dit ook kan.
Hieronder vind je enkele veelvoorkomende fouten die ervoor zorgen dat webpagina’s niet worden gecrawld.
Navigatiemenu’s zijn niet geschreven in HTML
Google en Bing zijn de laatste jaren steeds beter geworden in het lezen van Javascript, maar begrijpen dit nog niet zo goed als HTML. Je navigatiemenu is dusdanig belangrijk dat je deze altijd moet worden geschreven in HTML.
Mobiele navigatie verschilt met de desktop variant
Zoals eerder aangegeven is de mobiele navigatie tegenwoordig leidend. Als deze bijvoorbeeld minder uitgebreid is dan de desktop variant kan het zijn dat er pagina’s over het hoofd worden gezien.
Personalisatie
Krijgen verschillende bezoekers verschillende webpagina’s te zien? Let dan goed op! Een zoekmachine kan dit zien als cloacking.
Zo controleer je of je website goed wordt gecrawld
Je weet nu waar je allemaal op moet letten zodat je zeker weet dat zoekmachines je website kunnen bereiken. Maar hoe controleer je nu of jouw website wordt gecrawld?
Controleer het via de SERP
Heeft je website minder dan 500 pagina’s? Dan kun je door middel van een simpele zoekopdracht snel zien hoeveel pagina’s (en welke pagina’s) er allemaal zichtbaar zijn in de SERP. Gebruik hiervoor de geavanceerde zoekoperator site:.

Dekkingsrapport in Google Search Console
Heeft je website meer dan 500 pagina’s, dan kun je beter gebruik maken van het Dekkingsrapport in Google Search Console. Dit rapport laat namelijk gedetailleerder zien hoeveel pagina’s er geïndexeerd zijn en wijst je gelijk op eventuele fouten.

Wat is indexeren
Tijdens het crawlen wordt er een kopie van de webpagina gemaakt. Deze kopie wordt in de zogenaamde zoekindex geplaatst. De zoekindex van Google heet bijvoorbeeld Caffeine.
In deze zoekindex worden kopieën van alle gecrawlde pagina’s in wereld opgeslagen. Je kunt het zien als een grote database, of als een bibliotheek.
In de zoekindex worden pagina’s volledig geanalyseerd en probeert de zoekmachine jouw webpagina zo goed mogelijk te begrijpen. Er wordt onder andere gekeken naar:
- Koppen en subkoppen
- Tekstuele content
- Metadata
- Alt attributen
- Afbeeldingen
- Video’s
Daarnaast kijkt de zoekmachine of de pagina een duplicaat is of een canonical URL heeft. Is dit het geval, dan zal de pagina in het vervolg minder vaak worden gecrawld.
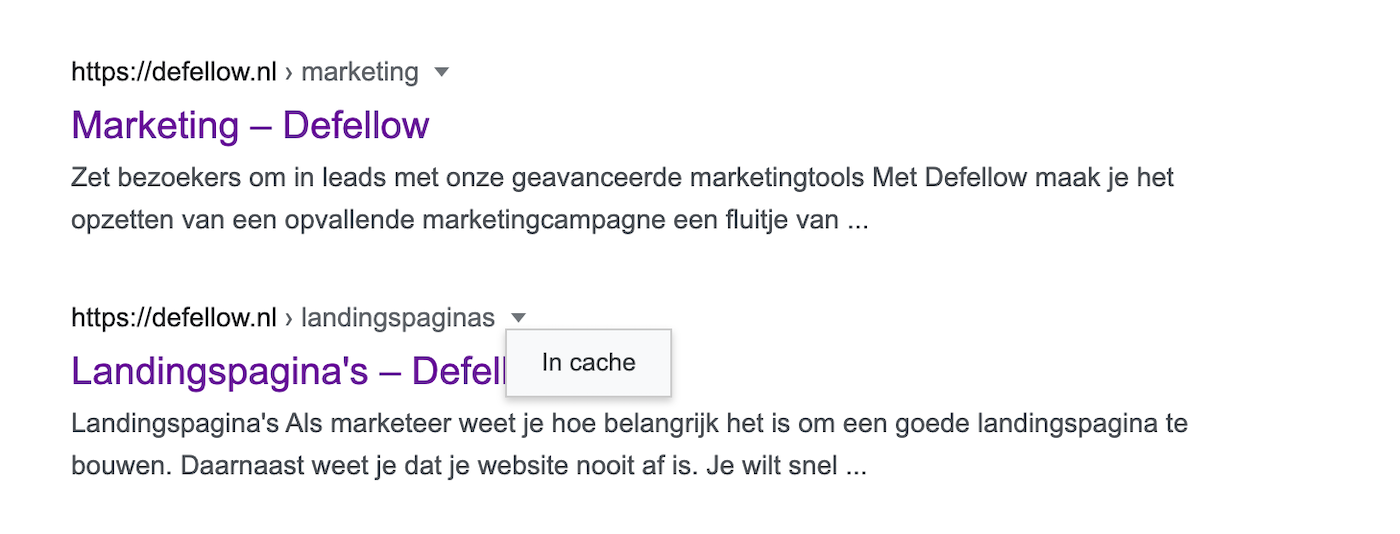
Hoe is jouw website opgeslagen in de zoekindex?
Via de SERP kun je bekijken hoe Google jouw website interpreteert. Gebruik hiervoor weer de geavanceerde zoekoperator site:. Klik naast de URL van een zoekresultaat op het driehoekje en vervolgens op ‘In cache‘.
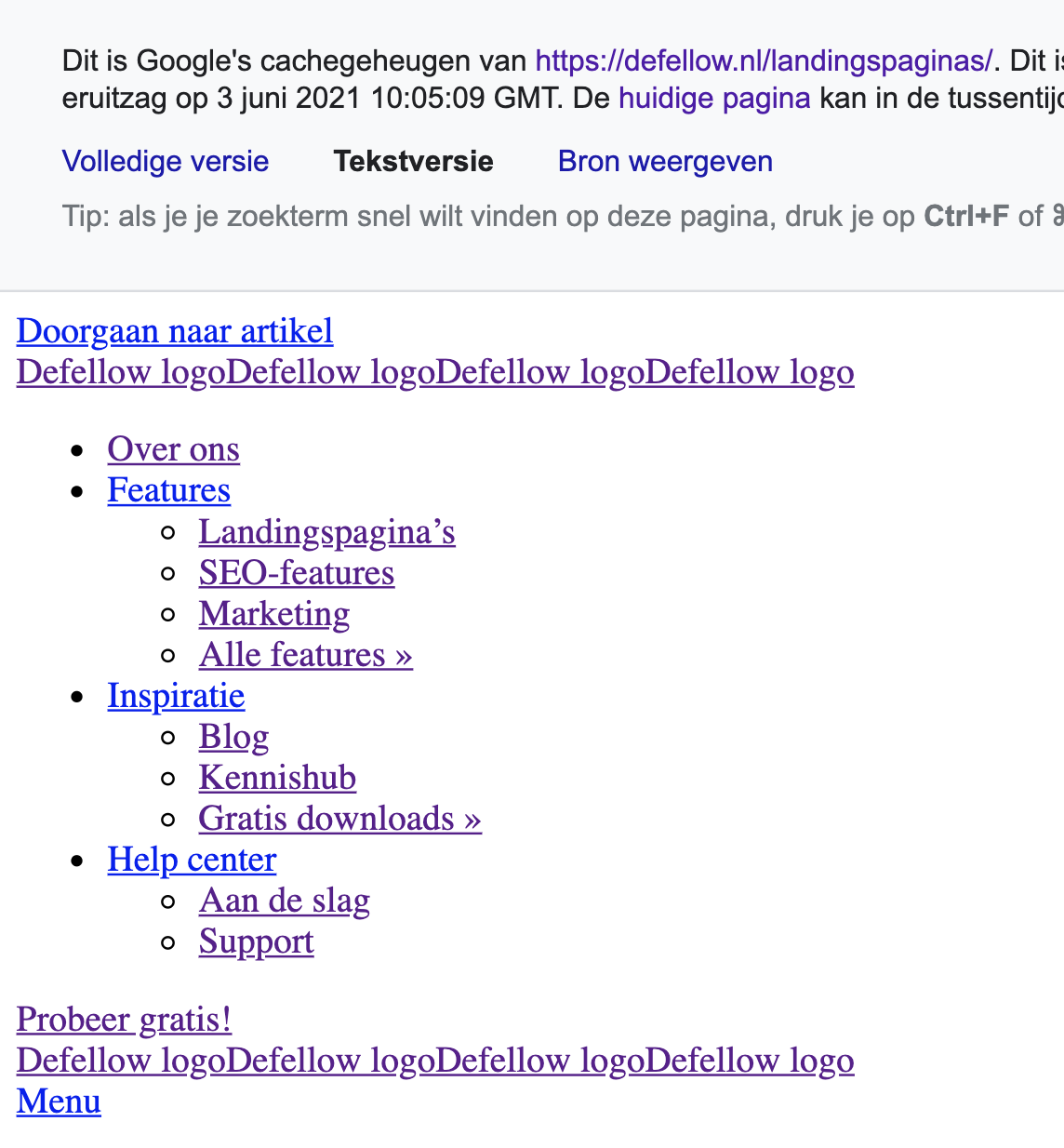
Je ziet nu hoe Google de desbetreffende pagina heeft opgeslagen. Daarnaast kun je via de optie ‘Tekstversie‘ controleren of Google de tekst op je website goed kan lezen (en dus begrijpen).
Zorg dat je wordt geïndexeerd
Het kan zijn dat je website wel gecrawld wordt, maar niet wordt geïndexeerd. Hier zijn verschillende redenen voor.
- Je maakt gebruik van een
no-indextag. - De pagina retourneert een niet gevonden– (4XX) of serverfout (5XX).
- De pagina is in strijd met de richtlijnen van de zoekmachine en hierdoor heb je een penalty gekregen.
Ranken (rangschikken)
Wanneer je een zoekopdracht uitvoert, genereert de zoekmachine binnen een aantal milliseconden een lijst met pagina’s die mogelijk antwoord geven op jouw zoekopdracht. Dat kan zo extreem snel omdat de data al zo goed is gestructureerd in de zoekindex.
In de onderstaande voorbeeld zie je bijvoorbeeld dat Google in 0,52 seconden 958.000 resultaten heeft gevonden voor de zoekopdracht appeltaart recept.
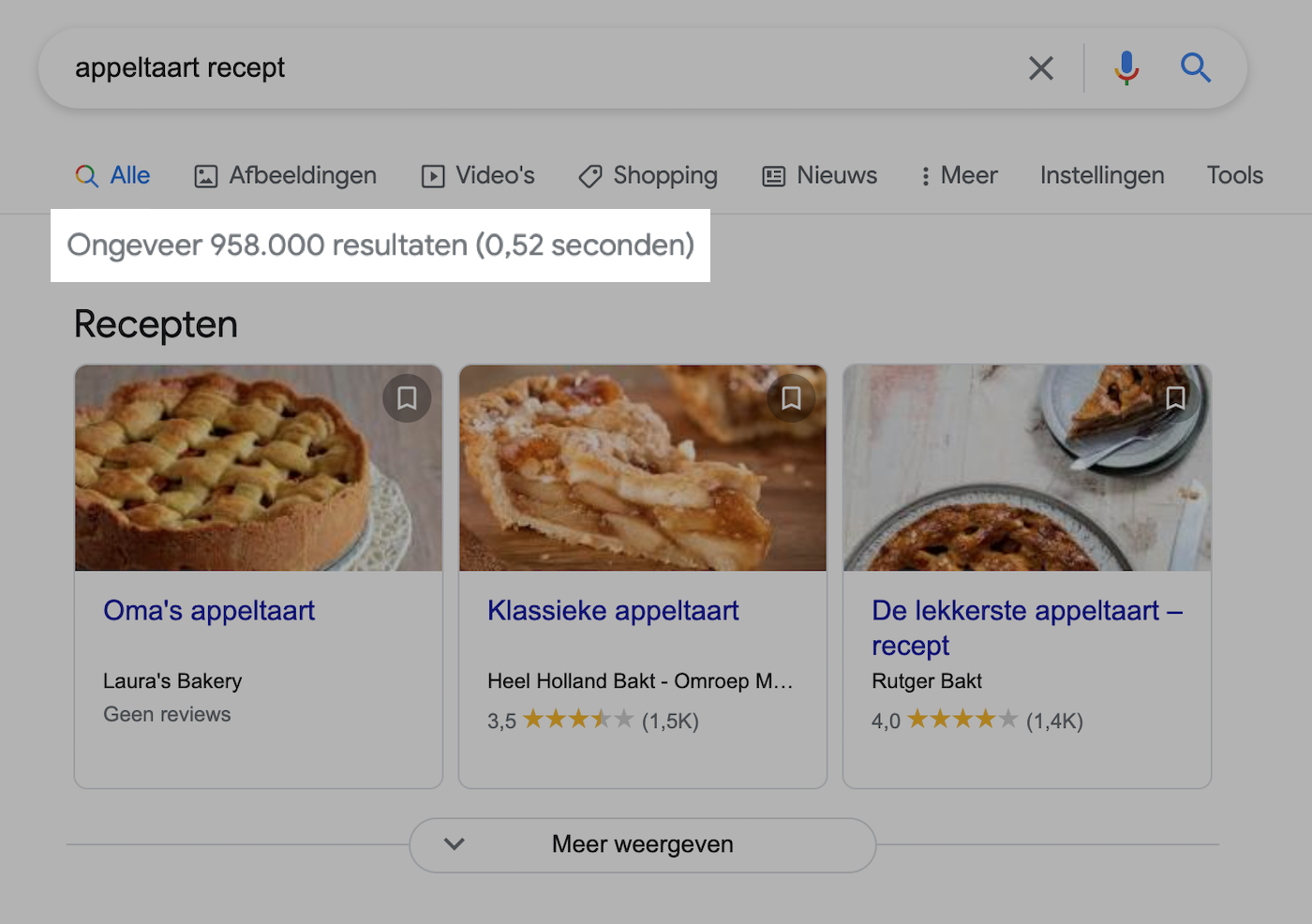
In die 0,52 seconden is er niet alleen een complete lijst uit de zoekindex opgehaald, deze lijst is ook gerangschikt.
Het rangschikken (of ranken) van alle resultaten doet een zoekmachine aan de hand van een algoritme.
Het algoritme zorgt ervoor dat je specifieke resultaten krijgt die voor jou relevant zijn.
Stel, je bent opzoek naar een pizzeria in de buurt. Dan voer je de zoekopdracht pizzeria uit. Of nog specifieker: pizzeria in de buurt.
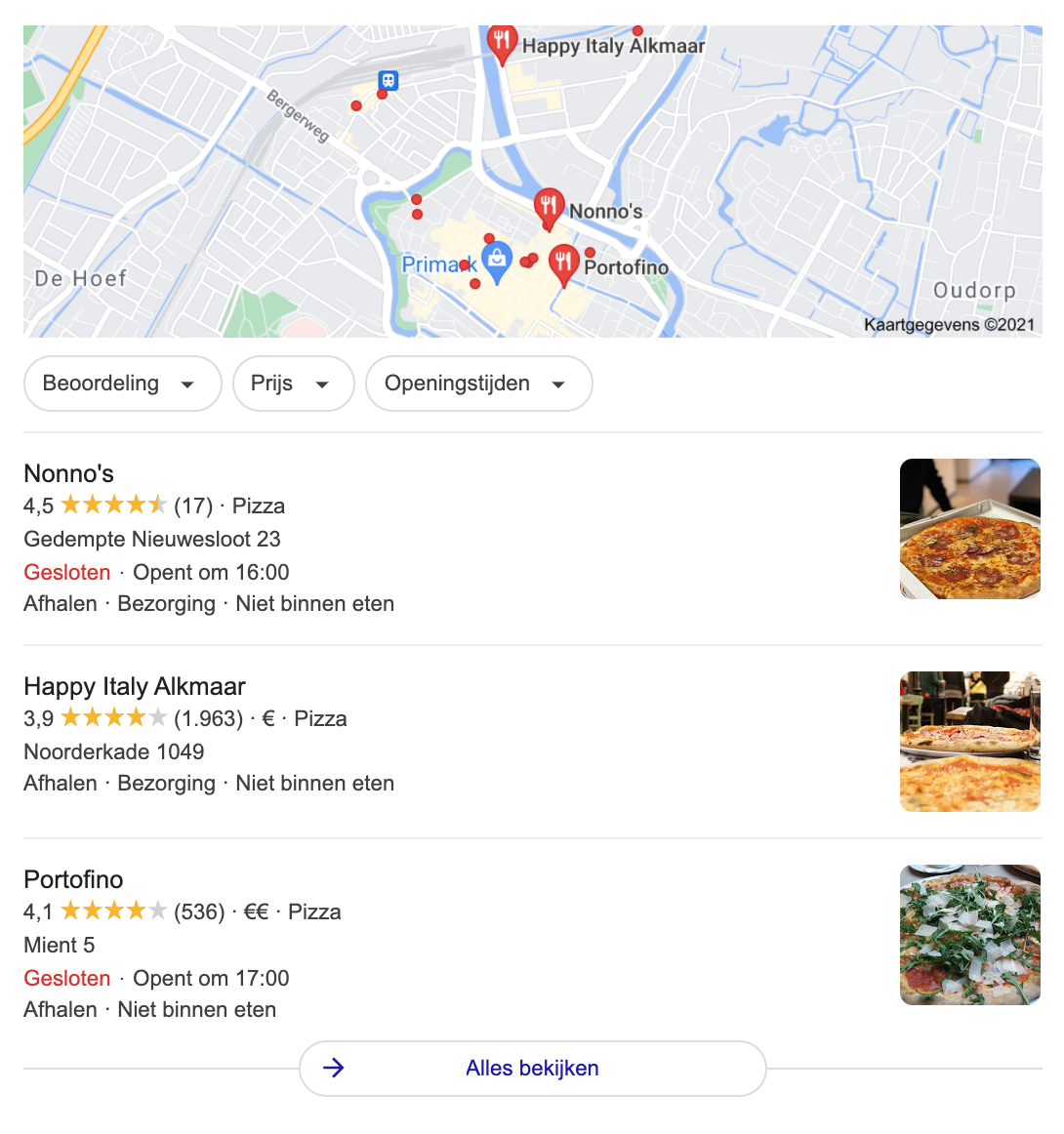
Ik woon in Alkmaar, dus ik verwacht ook een lijst met pizzaria’s in Alkmaar. De kans is groot dat jij compleet andere zoekresultaten verwacht
Een ander voorbeeld is van woorden met meerdere betekenissen (polysemie).
Stel, je voert de zoekopdracht maximum snelheid jaguar uit. Naar welk resultaat ben je dan opzoek?
Deze:

Of deze?

Het algoritme van Google zal het resultaat baseren op je eerdere zoekgeschiedenis.
Bij het rangschikken kijkt Google naar meer dan 200 factoren. In de basis kun je deze factoren opdelen in drie categorieën:
- Relevantie
- Autoriteit
- Versheid
Relevantie
Als je zoekt naar een appeltaart recept, dan ben je niet geïnteresseerd in resultaten voor een kersentaart recept en je bent waarschijnlijk ook niet opzoek naar de geschiedenis van de appeltaart.
Daarom kijkt Google in de eerste instantie welke pagina’s in de SERP relevant zijn. Het kijkt daarbij onder andere naar:
- De context: Hoe vaak en op welke plaatsen komt het zoekwoord voor op de pagina. Komen de zoekwoorden voor in de titel tag, (sub)koppen, URL en natuurlijk in de content?
- LSI zoekwoorden: Bevat de pagina zoekwoorden die conceptueel gerelateerd zijn aan het hoofdonderwerp?
De zoekmachine is de laatste jaren steeds beter geworden om zelf een inschatting te maken wat het beste zoekresultaat is (zeker sinds updates als BERT en RankBrain).
Maar om er zeker van te zijn dat het beste resultaat bovenaan in Google komt, kijkt het ook naar de autoriteit van een webpagina.
Autoriteit
Een belangrijke rankingfactor is de autoriteit van een website. Google meet dit aan de hand van backlinks.
Backlinks laten zien dat andere websites jouw webpagina waarderen en dat de informatie betrouwbaar is. Je kunt dit vergelijken met citaties/bronvermeldingen in een boek of rapport.
Vroeger was het vooral belangrijk om zoveel mogelijk backlinks te vergaren. Hierdoor kwamen er complete linkfarms waar je backlinks kon kopen. Dit is een vorm van black hat SEO. Iets waar je beter ver van weg kan blijven.
Vandaag de dag kijkt Google niet alleen naar het aantal backlinks, maar vooral naar de kwaliteit van de backlink. Hierdoor heeft het geen zin meer om backlinks te kopen. Sterker nog, het kan leiden tot lagere rankings, of zelfs een penalty.
Gebruiksgemak
Gebruiksgemak wordt een steeds belangrijker onderdeel van SEO. Om je bezoekers een unieke beleving te bieden moet je ervoor zorgen dat de volgende twee onderdelen goed voor elkaar zijn.
Mobielvriendelijk
Eerder kon je lezen dat Google is overgestapt naar mobile first indexing. Google is hier al in 2016 mee gestart. Vanaf dat moment gebruikte mensen de zoekmachine vaker via hun mobiel dan via de desktop.
Zorg er dus voor dat je website mobiel vriendelijk is. Google heeft een handige SEO-tool ontwikkeld waarmee je kunt kijken of je pagina mobiel vriendelijk is.

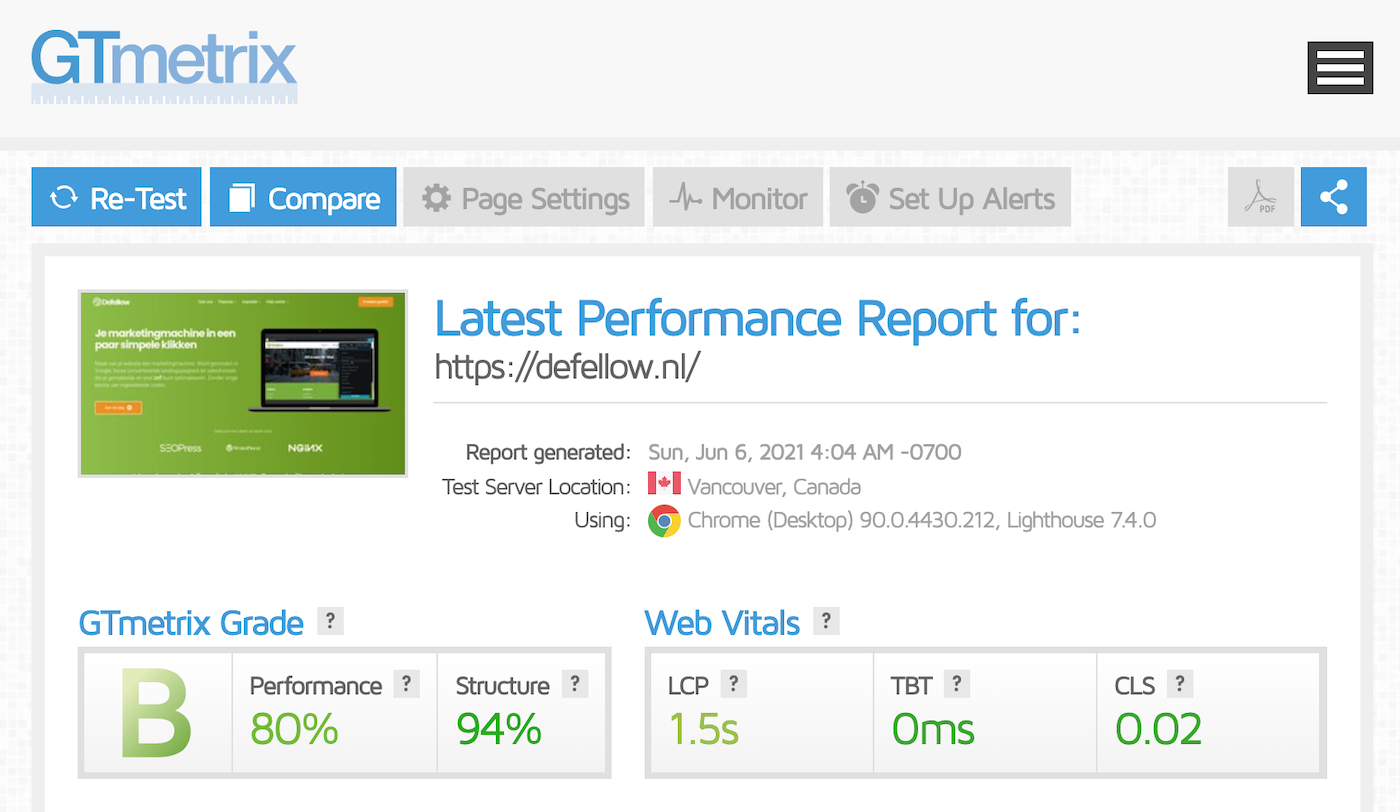
Snelle laadtijden
Uit verschillende onderzoeken van Google is gebleken dat een snelle laadtijd van je website ontzettend belangrijk is. Laadt je website niet binnen 3 seconden, dan is een groot deel van je bezoekers alweer vertrokken.
Sinds dit jaar heeft Google met Core Web Vitals zelfs harde cijfers gegeven waar jouw website aan moet voldoen. Voldoe je hier niet aan? Dan kan dit je rankings gaan schaden.
Met tools als PageSpeed Insights en GT Metrix kun je de snelheid van je website testen.