Het robots.txt bestand is een belangrijk tekstbestand op het gebied van SEO. Hierin vertel je namelijk welke pagina’s er wel en niet gecrawld mogen worden. In dit artikel lees je alles over het robots.txt bestand.
- Wat is een robots.txt bestand
- Waarom zou je gebruik maken van robots.txt
- Stappenplan: een robots.txt bestand maken
Wat is een robots.txt bestand
Het robots.txt bestand is een simpel tekstbestand dat zoekmachines vertelt welke pagina’s (en bestanden) op de website wel en niet gecrawld mogen worden.
Een voorbeeld van een robots.txt bestand:
Sitemap: https://voorbeeld.nl/sitemap.xml
User agent: Bingbot
Disallow: /blog/
Allow: /blog/blog-bericht-1/Dit ziet er misschien ingewikkeld uit, maar met enige context is het robots.txt bestand relatief makkelijk te lezen. Zo kun je uit het bovenstaande voorbeeld het volgende opmaken:
- De sitemap van de website bevindt zich op de locatie:
https://voorbeeld.nl/sitemap.xml - De user agent genaamd Bingbot (dit is de web crawler van Bing) mag de URL’s die beginnen met
https://voorbeeld.nl/blog/niet crawlen. - De URL
https://voorbeeld.nl/blog/blog-bericht-1/is hierop de uitzondering. - In het bestand staan geen richtlijnen voor andere user agents. Deze mogen dus alle pagina’s crawlen.
Kortgezegd geef je in dit bestand richtlijnen aan verschillende user agents.
Belangrijk om te weten: De inhoud van een robots.txt bestand is een richtlijn. Grote zoekmachines (zoals Google, Bing of DuckDuckGo) respecteren deze richtlijnen, maar er zijn er ook een aantal die dit niet doen.
User agent
Een user agent is het computerprogramma dat bij een netwerkfunctie of protocol hoort.
In het geval van zoekmachines is de user agent de naam van de web crawler. Hieronder vind je de namen van de bekendste zoekmachines en hun crawlers.
| Zoekmachine | User agent |
|---|---|
| Googlebot | |
| Google afbeeldingen | Googlebot-Image |
| Bing | Bingbot |
| DuckDuckGo | DuckDuckBot |
| Yahoo! | Slurp |
| Yandex | Yandex |
Ook verschillende SEO tools maken gebruik van user agents. Hieronder vind je enkele veelgebruikte.
| SEO tool | User agent |
|---|---|
| Ahrefs | AhrefsBot |
| Majestic | MJ12bot |
| Screaming Frog | Screaming Frog SEO Spider |
| Semrush | SemrushBot & SemrushBot-SA |
Als je bijvoorbeeld alleen richtlijnen wilt geven aan Google en Bing, doe je dat als volgt.
User agent: Googlebot
[richtlijn 1]
[richtlijn 2]
User agent: Bingbot
[richtlijn 1]
[richtlijn 2]Iedere keer als je met een nieuwe user agent aangeeft, begint deze met een schone lei. Je moet het dus echt zien als aparte groepen. In het bovenstaande voorbeeld gelden de richtlijnen voor de Googlebot dus niet voor de Bingbot (of andersom).
Wildcard
Het is ook mogelijk om een wildcard te gebruiken. Hiermee geef je aan dat de richtlijnen gelden voor alle user agents. Je gebruikt de wildcard door middel van een sterretje (*).
User agent: *
[richtlijn 1]
[richtlijn 2]User agents kijken altijd naar de richtlijnen die het meest nauwkeurig voor hen van toepassing zijn.
In het onderstaande voorbeeld negeert Google de wildcard en volgt het de richtlijnen voor de Googlebot:
User agent: *
[richtlijn 1]
[richtlijn 2]
User agent: Googlebot
[richtlijn 1]
[richtlijn 2]Richtlijnen
De richtlijnen zijn de regels die je geeft aan de eerder gedefinieerde user agent. In het robots.txt bestand definieer je eerst een richtlijn en geef je vervolgens aan voor welke URL(‘s) deze van toepassing zijn.
Google ondersteunt de volgende drie richtlijnen:
- Disallow
- Allow
- Sitemap
Disallow
Hiermee geef je aan dat bepaalde pagina’s niet mogen worden gecrawld.
Als je bijvoorbeeld wilt dat de producten op je website nog niet worden getoond in zoekresultaten, dan kun je dat op de volgende manier aangeven:
User-agent: *
Disallow: /product/Niet alleen de URL /product/ wordt in dit geval niet gecrawld, maar alle pagina’s die beginnen met dit pad. Dus ook:
/product/product-1//product/product-2//product/product-3/
Allow
Met de allow richtlijn geef je aan welke pagina’s wel gecrawld mogen worden. Je gebruikt deze regel alleen om een eerdere instructie te overschrijven.
User-agent: *
Disallow: /product/
Allow: /product/product-1/In het bovenstaande voorbeeld geef je aan dat /product/product-1/ wel gecrawld mag worden, maar alle andere pagina’s niet (waaronder /product/product-2/ en /product/product-3).
Sitemap
Met de sitemap richtlijn vertel je de user agents op welke URL de XML-sitemap zich bevindt. Je hoeft deze richtlijn niet voor iedere user agent opnieuw aan te geven.
Voorbeeld van een robots.txt bestand met een sitemap richtlijn:
Sitemap: https://defellow.nl/sitemaps/page-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/post-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/product-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/hub-sitemap1.xml
User-agent: *
Disallow: /product/
Allow: /product/product-1/Je ziet hier dat er voor iedere sitemap een aparte richtlijn is toegevoegd.
Waarom zou je gebruik maken van robots.txt
Als je een klein blog hebt is het waarschijnlijk niet persé nodig om een robots.txt bestand te hebben. Je pagina bestaat namelijk uit dusdanig weinig pagina’s dat zoekmachines hun weg wel weten te vinden en de kans op duplicate content is beperkt.
Een manier om te bepalen of een robots.txt bestand toegevoegde waarde heeft voor jouw website, is door deze te Googlen.
In het onderstaande voorbeeld zie je bijvoorbeeld dat er een archiefpagina van de maand september is geïndexeerd.

Eigenlijk wil ik niet dat dit soort pagina’s worden geïndexeerd. In dit geval kun je ervoor kiezen deze op te nemen in het robots.txt bestand.
Webshops met filters
Webshops die gebruik maken van filters raad ik altijd aan om een robots.txt bestand te maken. Filters voegen namelijk parameters toe aan een URL, wat al snel resulteert in honderden vergelijkbare (maar voor een zoekmachine verschillende) pagina’s.
Dit kan verschillende SEO gerelateerde problemen opleveren, zoals:
- Duplicate content.
- Overbelasting van de server.
- Verspilling van het crawlbudget.
- Indexering van verkeerde pagina’s (dit kan wel voorkomen worden met behulp van een canonical tag)
In het onderstaande stappenplan lees je hoe je URL’s met parameters kunt toevoegen aan het robots.txt bestand.
Stappenplan: een robots.txt bestand maken.
- Maak een tekstbestand genaamd robots.txt
- Richtlijnen voor user agents toevoegen
- Het robots.txt bestand controleren
Maak een tekstbestand genaamd robots.txt
Je kunt op verschillende manieren een robots.txt bestand aanmaken.
Handmatig een tekstbestand aanmaken
Als je toegang hebt tot de filemanager van je website kun je handmatig een nieuw bestand aanmaken genaamd robots.txt. Dit bestand moet geplaatst worden in de hoofdmap.

Het is ook mogelijk om op je lokale computer een tekstbestand te maken en deze te uploaden in je hoofdmap. Je kunt gewoon gebruik maken van het Kladblok. Let daarbij wel op dat je het bestand bewaart in een UTF-8 codering.
Als je geen toegang hebt tot je file manager kun je gebruik maken van een plugin. Hieronder behandel ik twee bekende plugins, namelijk Yoast SEO en SEOpress.
Robots.txt bestand maken met de Yoast SEO plugin
Als je gebruik maakt van de Yoast SEO plugin kun je (ook in de gratis versie) gemakkelijk een robots.txt bestand aamaken.
Ga in het WordPress menu naar SEO → Gereedschap → Bestandseditor.

Klik vervolgens op Maak robots.txt bestand aan.

Er wordt nu een robots.txt bestand aangemaakt in de hoofdmap van je website.
Een virtueel robots.txt bestand aanpassen met SEOpress
WordPress maakt standaard gebruik van een zogenaamd virtueel robots.txt bestand. Wanneer je gebruik maakt van WordPress heb je dus automatisch een robots.txt bestand. Je kunt dit testen door /robots.txt toe te voegen aan je domeinnaam (dus bijvoorbeeld https://defellow.nl/robots.txt).
Standaard heeft dit bestand de volgende inhoud:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpDit bestand bestaat niet fysiek op je server. Met SEOpress is het mogelijk om het virtuele robots.txt bestand aan te passen.
Ga naar SEO → PRO → robots.txt.
Hier kun je vervolgens het virtuele robots.txt bestand aanpassen.
Richtlijnen voor user agents toevoegen
Nu het bestand is aangemaakt is het tijd om de richtlijnen toe te voegen voor verschillende user agents. Ik start met de volgende code.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpDeze code wordt automatisch door WordPress toegevoegd en zorgt ervoor dat de admin omgeving niet wordt gecrawld.
Sitemap richtlijn toevoegen
Als eerst voeg ik mijn sitemaps toe. Deze zet ik bovenaan in het bestand.
Sitemap: https://defellow.nl/sitemaps/page-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/post-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/product-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/hub-sitemap1.xml
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpDatum archief
Eerder in dit blog kwam ik erachter dat er automatische datumarchieven worden aangemaakt. Deze archieven hebben de volgende URL-structuur:
https://defellow.nl/jaartal/maandnummer/
Wat mij betreft hebben deze pagina’s geen toegevoegde waarde.
Ik sluit ze daarom voor alle user agents uit door middel van de disallow richtlijn:
Sitemap: https://defellow.nl/sitemaps/page-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/post-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/product-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/hub-sitemap1.xml
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /2021/
Disallow: /2022/Winkelwagen en checkout
Ook de winkelwagen en checkout pagina hebben geen toegevoegde waarde in de SERP. Daarom sluit ik ook deze pagina’s uit.
Sitemap: https://defellow.nl/sitemaps/page-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/post-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/product-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/hub-sitemap1.xml
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /2021/
Disallow: /2022/
Disallow: /afrekenen/
Disallow: /winkelwagen/Om zeker te weten dat deze pagina’s niet in de zoekresultaten verschijnen kun je ze het best ook een noindex tag geven.
Filters
De filters van je website zijn waarschijnlijk het belangrijkst om in je robots.txt bestand op te nemen.
De filters op deze website zijn te gebruiken op de algemene winkel pagina (https://defellow.nl/winkel/) en de verschillende productcategorieën (https://defellow.nl/productcategorie/categorienaam/)
Iedere keer als er een filter wordt toegepast wordt er een parameter aan de URL toegevoegd. Deze parameter begint altijd met een vraagteken (?). Daarom sluit ik alles na de vraagteken uit.
Sitemap: https://defellow.nl/sitemaps/page-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/post-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/product-sitemap1.xml
Sitemap: https://defellow.nl/sitemaps/hub-sitemap1.xml
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /2021/
Disallow: /2022/
Disallow: /afrekenen/
Disallow: /winkelwagen/
Disallow: /winkel/?
Disallow: /product-categorie/*/?Je kunt de wildcard (*) niet alleen gebruiken voor user agents, maar dus ook voor categorieën. In het bovenstaande voorbeeld geld de disallow richtlijn dus voor alle product categorieën.
Nu alle richtlijnen zijn doorgevoerd kun je deze invoeren via één van de eerder genoemde mogelijkheden.
Robots.txt bestand testen
Nu je het robots.txt bestand hebt aangepast is het belangrijk om deze goed te testen.
Robots.txt tester tool
Google heeft een handige robots.txt tester tool ontwikkeld. Met deze tool kun je je website actief testen. Voer een URL in en je ziet direct of deze geblokkeerd wordt.
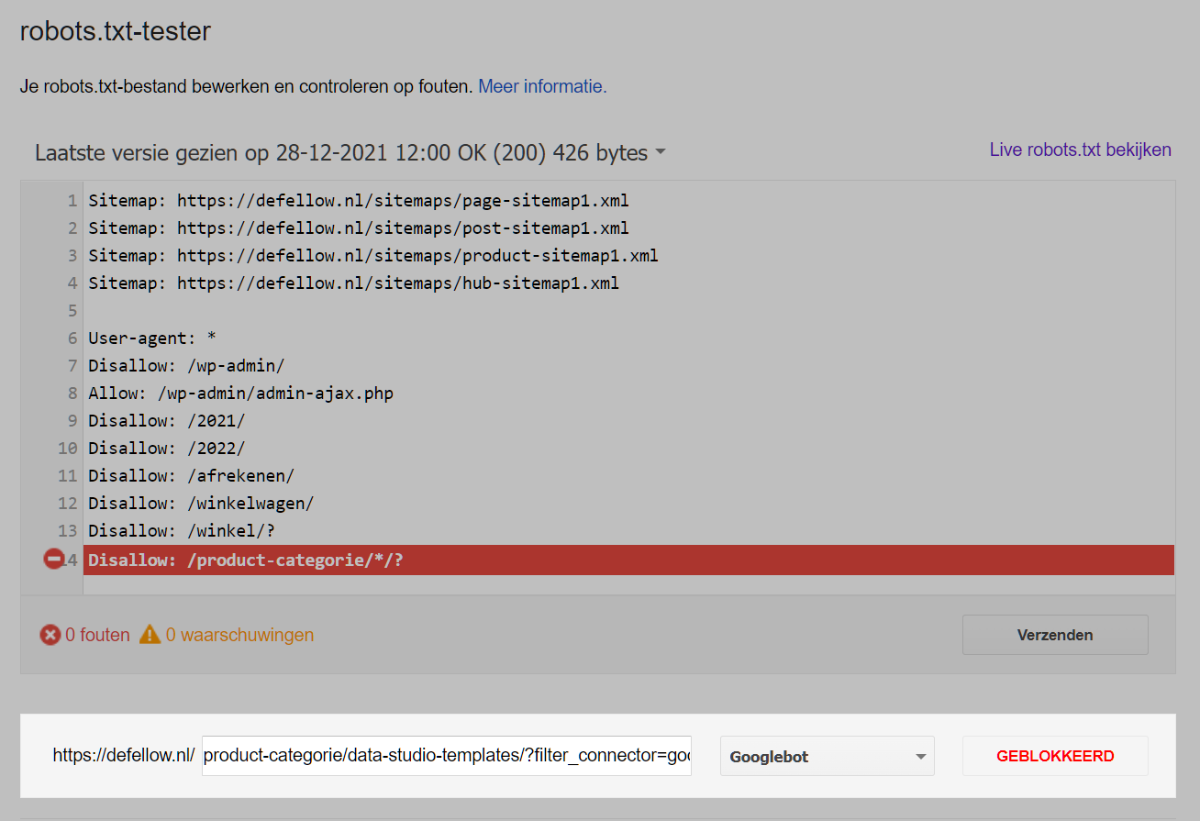
Test ook goed of de pagina’s waarvan je wilt dat deze gecrawld worden dat ook daadwerkelijk worden.